
SHAPING THE DIGITAL FUTURE
Our global organisational structure and the development programme for:ward pave the way to becoming a digital platform company.

OUR TECH STACK
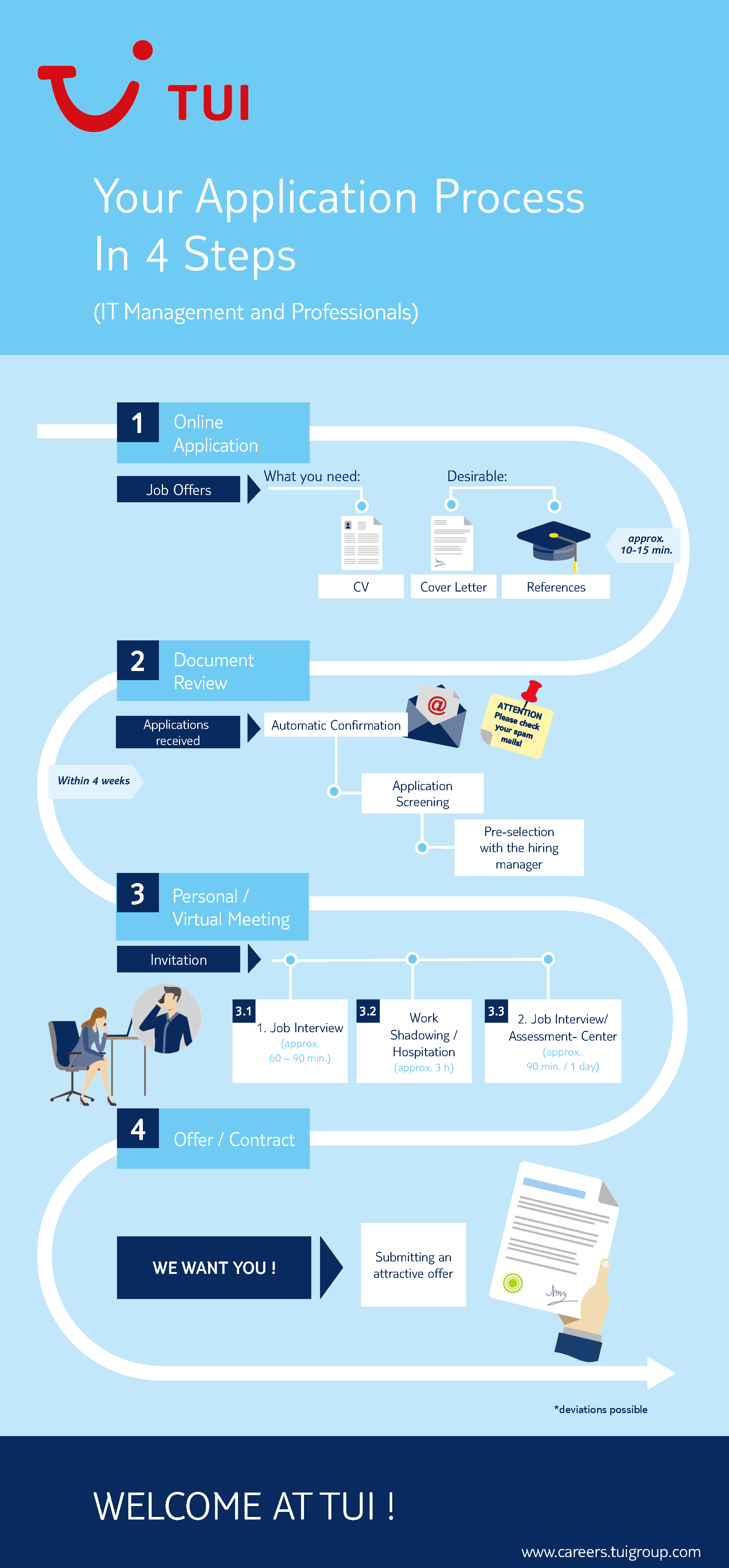
TUI is influencing and shaping the digital world of travel. To achieve this and to set the pace in an increasingly digital environment, it requires the latest and most innovative technologies, tools, systems and working methods.











TUI Tech Blog
Latest posts


EXPLORE OUR DIGITAL & TECHNOLOGY OPPORTUNITIES
| Job Title | Location | |
|---|---|---|
| Android Software Engineer | Flexible … | |
| Application Manager für touristische IT-Anwendungen (all gender) | Hamburg, Germany | |
| Back End Software Engineer | Flexible … | |
| Back End Software Engineer | Flexible … | |
| Back End Software Engineer | Flexible … | |
| Back End Software Engineer | Flexible … | |
| Back End Software Engineer | Flexible … | |
| Back End Software Engineer | Flexible … | |
| Backend Software Entwickler (m/w/d) | Hanover, Germany | |
| Business Analyst – Flight IT | Flexible … | |
| Business Intelligence & Reporting Manager | Flexible … | |
| Business Owner TUI App (m/w/d) | Flexible … | |
| Data Engineer – Hotels & Resorts IT | Flexible … | |
| DevOps Engineer | Flexible … | |
| Digital Workplace Engineer (m/f/d) | Flexible … | |
| Expert Quality & Testing (m/w/d) | Hanover, Germany | |
| Full Stack Developer (m/w/d) | Flexible … | |
| Full Stack Software Engineer | Flexible … | |
| Full Stack Software Engineer | Flexible … | |
| Full Stack Software Engineer – Platform Solutions | Flexible … |
Results 1 – 20 of 77
See all jobs